6.1 Introduction
만약 이 책을 읽고 있다면, 아마 당신은 이미 많은 R 함수들을 만들어 봤을거다.
그리고 코드에서 단순 반복을 제거하려면 어떻게 해야할 줄도 알고 있고.
이 챕터에서는, 그 비형식적이고 실습으로 배운 지식을,
좀 더 단단하고 이론적인 이해로 바꿀 것.
흥미로운 트릭들이랑 테크닉들을 보게 될 건데,
여기서 배우는 것들은 나중에 나오는 advanced 토픽들을 이해하는데 있어 중요하다는 걸 인지하자.
Quiz
다음의 문제들을 보고, 이 챕터를 스킵할 수 있을지 확인해보셈.
답은 Section 6.9에 있다.
1. 함수의 3 요소components는?
- 다음의 코드는 무엇을 return하는가?
x <- 10
f1 <- function(x) {
function() {
x + 10
}
}
f1(1)()
- 다음의 코드를 통상적인 표현으로는 어떻게 쓸 수 있을까?
`+`(1, `*`(2, 3))
- 어떻게 하면 다음의 코드를 좀 더 읽기 쉽게 만들 수 있을까?
mean(, TRUE, x = c(1:10, NA))
- 다음의 코드는 실행되었을 때 에러가 나올까 안 나올까? Why or why not?
f2 <- function(a, b) {
a * 10
}
f2(10, stop("This is an error!"))
-
infix 함수란 무엇인가? 어떻게 만들 수 있는가?
대체 함수는 무엇인가? 어떻게 만들수 있는가? -
함수를 어떻게 exit하던간에, cleanup action이 실행된다고 어떻게 보장할 수 있는가?
Outline
6.2 Function fundamentals
R에서 함수를 이해하기 위해서는, 2개의 아이디어를 이해해야 한다.
1. 함수는 3개의 요소components로 쪼갤 수 있다.
요소arguments, 본체body 그리고 environment
얘는 그냥 env라고 해야지.
모든 규칙들rules은 예외가 있다.
그리고 이 1번의 경우엔, "원시primitive" base 함수들이 있다.
이것들은 온전히 C 언어로만 고안implement되었다.
- 함수Function는 오브젝트다. 벡터vector도 오브젝트이듯이.
6.2.1 Function components
함수는 3가지 파트가 있다.
1. formals(): 어떻게 함수를 호출할건지 컨트롤할 수 있는 요소arguments들의 리스트
-
body(): 함수 안의 코드. the code inside the function -
environment(): 어떻게 함수가, 이름들과 연관되어 있는 값을 찾는지, 이걸 결정하는 데이터 구조
formals와 body는, 함수를 만들 때 명백하게 정해줘야explicitly specify하는데,
environment는, 어디에 만드냐에 따라 implicit하게 specify 된다.
function env는 항상 존재한다.
하지만, 함수가 global env에 정의되어 있지 않을때에만 프린트된다.
it is only printed when the function isn't defined in the global env.
f02 <- function(x, y) {
# A comment
x + y
}
formals(f02)
## $x
##
##
## $y
body(f02)
## {
## x + y
## }
environment(f02)
## <environment: R_GlobalEnv>
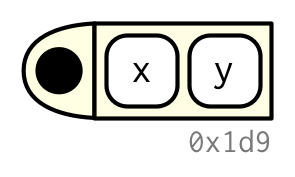
함수를, 아래의 다이어그램처럼 그려볼 것이다.
왼쪽의 검은 점은 env다. 오른쪽 2개의 블락들blocks은 함수의 인자들arguments이다.
body는 안 그릴 것이다.
왜냐하면 보통 양이 많고, 함수의 shape을 이해하는데 별 도움이 안 되기 때문.
 { width = 50% }
{ width = 50% }
R의 모든 오브젝트들과 마찬가지로, 함수들도 몇 개든 상관없이 추가적인 특성들attributes()을 가질 수 있다.
base R에 의해 사용된 하나의 특성은 srcref인데, source reference의 줄임말이다.
함수를 만드는데 사용된 소스코드를 알려준다.
srcref는 프린팅하는데 사용된다.
왜냐하면, body()와는 다르게, 코드 코멘트들이랑 다른 포매팅들도 갖고 있기 때문.
attr(f02, "srcref")
## function(x, y) {
## # A comment
## x + y
## }
6.2.2 Primitive functions
함수는 3개의 파트를 갖는다는 이 규칙에는, 하나의 예외가 있다.
원시primitive 함수들, sum()이나 [와 같은 것들은, C 코드를 직접적으로 호출한다.
sum
## function (..., na.rm = FALSE) .Primitive("sum")
`[`
## .Primitive("[")
이것들은, 타입 builtin이나 타입 special을 갖고 있다.
typeof(sum)
## [1] "builtin"
typeof(`[`)
## [1] "special"
이 함수들은 애초에 R이 아닌, C로 존재하기 때문에,
이것들의 formals(), body(), environment()는 전부 NULL이다.
formals(sum)
## NULL
body(sum)
## NULL
environment(sum)
## NULL
원시 함수들은 base 패키지에서만 발견된다.
분명한 퍼포먼스적인 이점이 있지만, 대가가 있다.
더 작성하기가 힘들다. harder to write.
이러한 이유에서, R-코어팀은 다른 옵션이 없는게 아니라면, 이 방법을 쓰지 않는다.
6.2.3 First-class functions
R 함수가, 그 자체로 오브젝트라는걸 이해하는건 매우 중요하다.
이건 보통 "first-class functions"라고 부르는 언어 속성language property다.
많은 다른 언어들과는 다르게, 함수를 정의하고 이름 붙이는데 다른 특별한 문법syntax이 없다.
그냥 function()을 이용해서 함수 오브젝트function object를 만들고, <-를 이용해서 이름 붙이면 된다.
느낌
프로그래밍 언어가 퍼스트클래스 함수를 지원하면, 변수에 함수를 할당도 할 수 있고, 인자로써 다른 함수에 전달할 수도 있고, 함수의 리턴값으로도 쓸 수 있고.
f01 <- function(x) {
sin(1/ x ^ 2)
}
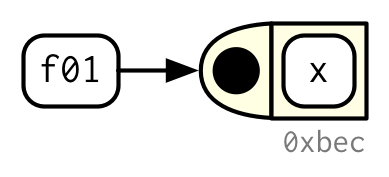
거의 항상, 함수를 만들고 나면 이름을 붙이겠지만, 이 이름을 붙이는 binding step이 꼭 요구되는 건 아니다.
이름을 안 붙이기로 결정했다면, 익명 함수anonymous function을 만든 것이다.
이름을 꼭 붙여야 할 필요가 없는 경우라면, 상당히 유용하다.
lapply(mtcars, function(x) length(unique(x)))
Filter(function(x) !is.numeric(x), mtcars)
integrate(function(x) sin(x) ^ 2, 0, pi)
마지막 옵션은, 리스트에다가 함수들을 넣는 것이다.
(아니 리스트에다 함수 넣는 것도 되는건 처음 알았네)
funs <- list(
half = function(x) x / 2,
double = function(x) x * 2
)
funs$half(10)
## [1] 5
funs$double(10)
## [1] 20
R에서, 종종 closures라는 함수를 볼 것이다.
이건, R 함수들이 자기 자신의 env를 캡쳐한다는 사실을 반영한 것이다.
Section 7.4.2에서 더 배우게 될 것이다.
6.2.4 Invoking a function
보통 함수를, 함수 이름에다 괄호를 열고, 인자들arguments을 넣고, 괄호를 닫는 식으로 호출한다.
예를 들어서, mean(1:10, na.rm = TRUE) 이렇게.
그런데 만약에 데이터 구조에 인자들을 이미 갖고 있는 경우에는 어떻게 할 수 있을까?
예를 들어서,
args <- list(1:10, na.rm = TRUE)
이렇게 갖고 인자들을 갖고 있는 것임.
do.call()을 쓰면 된다.
이 함수는 2개의 인자들arguments을 받는다.
하나는 호출할 함수 이름, 다른 하나는 함수 인자들을 가지고 있는 리스트.
do.call(mean, args)
## [1] 5.5
이 아이디어를 Section 19.6에서 다시 볼 것이다.
6.2.5 Exercises
6.3 Function composition
함수 합성.
base R은, 여러 개의 함수 호출을 합성하는데 있어, 2가지 방법을 제공한다.
예를 들어, sqrt()와 mean()을 바탕으로, 모표준편차population standard deviation를 계산하고 싶다치자.
square <- function(x) x ^ 2
deviation <- function(x) x - mean(x)
① 함수 호출들을 중첩nest시킬 수도 있고,
x <- runif(100)
sqrt(mean(square(deviation(x))))
## [1] 0.2887039
② 아니면 중간중간 결과물들을 변수로 저장할 수도 있다.
out <- deviation(x)
out <- square(out)
out <- mean(out)
out <- sqrt(out)
out
## [1] 0.2887039
위 2개는 base R이고,
③ magrittr 패키지(Bache and Wickham 2014)는 3번째 옵션을 제공한다.
이항 연산자binary operator인 %>%는, 파이프pipe라고 부르고, "and then"이라고 발음한다.
library(magrittr)
x %>%
deviation() %>%
square() %>%
mean() %>%
sqrt()
## [1] 0.2887039
x %>% f()는, f(x)와 같은 것이다.
x %>% f(y)는, f(x, y)와 같은 것이다.
파이프를 사용하면 낮은 수준의 데이터 흐름이 아니라, 높은 수준의 함수 구성에 집중할 수 있다.
초점은 수정 된 것(명사)이 아니라, 수행중인 것(동사)에 있다.
The pipe allows you to focus on the high-level composition of functions rather than the low-level flow of data;
the focus is on what's being done(the verbs), rather than on what's being modified(the nouns).
이러한 스타일은 하스켈이나 F#에서는 흔하다.
이게 magrittr을 만드는데 있어 영감이 되었고, Forth나 Factor라는 프로그래밍 언어의 디폴트 스타일이다.
(둘 다 이번에 처음 알게 된 프로그래밍 언어다.)
위에 소개한 3개의 옵션들은 각각 장단점이 있다.
-
Nesting은, (
f(g(x))같은) 간결하고, 짧은 시퀀스에 최적화되어있다.
하지만 길이가 길어질수록 읽기가 어려워진다. 왜냐하면 안에서부터 밖으로, 오른쪽에서부터 왼쪽으로 읽어야하기 때문.
결과적으로, 인자들arguments이 퍼지면서 Dagwood sandwich 문제를 발생시킬 수 있다.
별 대단한 문제는 아니고, 그냥 길어짐에 따라 함수랑 인자들이랑 거리가 멀어진다. 이게 진짜 다임. -
중간중간 결과물을 저장하는 것은, (
y <- f(x); g(y)이런 식)
중간 오브젝트들intermediate objects에 이름을 붙여줘야 한다.
만약 이 오브젝트들이 중요하다면 강점이 될 수 있겠는데, 그렇지 않다면 약점이다. -
Piping은, (
x %>% f() %>% g()) 그냥 그대로 읽으면 된다는 점에서 강점을 갖고 있다.
하던대로 왼쪽에서 오른쪽으로 읽으면 되고, 중간 오브젝트들에 이름을 붙일 필요도 없다.
하지만 하나의 오브젝트만을 선형 변환 시퀀스linear sequence of transformation로 사용할 수 있다.
그리고 magrittr이라는 3번째 패키지를 필요로 하고, 독자가 piping을 알고 있어야 한다는 문제가 있다.
대부분의 코드는 위 3가지 스타일의 조합을 사용한다.
그때그때 필요에 따라 3개 이것저것 쓴다.
그래도, Piping은 데이터 분석 코드에 좀 더 흔하다.
분석이라는게 하나의 오브젝트(예를 들어 데이터 프레임이나 plot)에 변형 시퀀스를 적용하는 것이다 보니깐.
패키지들에는 piping을 별로 안 쓴다.
이게 나쁜 아이디어라서가 아니라, 별로 내추럴하지 않아서.
6.4 Lexical scoping
Chapter 2에서, 할당assignment에 대해 배웠다.
이름name에다가 값value을 binding하는 행동.
여기서는 scoping에 대해 다룰 것인데, 이름과 연관associate된 값을 찾는 행동임.
scoping의 기본적인 룰은 꽤나 직관적이다.
대놓고 배우지는 않았더라도, 모르는 사이에 이미 어느 정도 알고 있을수도 있다.
예를 들어, 다음의 코드는 10과 20 중 어떤 값을 return할까?
x <- 10
g01 <- function() {
x <- 20
x
}
g01()
이 섹션에서는, scoping의 형식적인 룰들과 사소한 디테일들에 대해 배울 것이다.
scoping에 대해 깊이 이해하고 나면, 좀 더 advanced function programming 툴들을 사용할 수 있을 것이고,
R 코드를 다른 언어들로 번역할 수 있는 툴들을 작성할 수 있게 해준다.
R은 lexical scoping을 사용한다.
함수가 어떻게 정의되었는지를 바탕으로 이름name의 값value을 찾아본다.
어떻게 호출되었는지가 아니라.
R looks up the values of names based on how a function is defined, not how it is called.
여기서 "Lexical"은 word나 vocabulary라는 뜻이 아니다.
이건 기술적인 CS 단어다.
scoping rule이, run-time 구조가 아닌 parse-time을 사용한다는.
It’s a technical CS term that tells us that the scoping rules use a parse-time, rather than a run-time structure.
parse-time run-time
여기서 parse-time이랑 run-time이 무슨 뜻인지 한참 찾아봤는데,parse-time이라는건 위에 how a function is defined, 함수가 어떻게 정의되었는지와 관련이,
run-time이라는건 위에 how a function is called, 함수가 어떻게 호출되었는지와 관련이 있음.
그래서 lazy evaluation같이, 받아만 놓고 evaluate는 호출되었을 때만 하면 그게 run-time이랑 연관이,
입력한 즉시 evaluate가 되는 그런건 parse-time이랑 연관이 있는듯.
R의 lexical scoping은, 4개의 주요한 규칙들이 있다.
1. Name masking
2. Functions versus variables
3. A fresh start
4. Dynamic lookup
6.4.1 Name masking
lexical scoping의 기본 원리,
함수 안에서 정의된 이름name들은, 밖에서 정의된 이름들을 가린다.mask
그러니깐 밖에서 정의된 이름들이 함수 안에서 정의된 걸로 덮어씌워진다는 것.
하지만, 덮어씌운다고 한다면 override라고 했을텐데 mask라고 했으니 '가린다'라고 번역했다.
다음의 예를 보자.
x <- 10
y <- 20
g02 <- function() {
x <- 1
y <- 2
c(x, y)
}
g02()
## [1] 1 2
만약 이름이 함수 안에 정의되어 있지 않으면, R은 한 레벨 위를 찾아본다.
x <- 2
g03 <- function() {
y <- 1
c(x, y)
}
g03()
## [1] 2 1
그리고 이건 이전의 y값을 바꾸지는 않음
y
## [1] 20
어떤 함수가 다른 함수 안에서 정의되어 있다해도, 같은 규칙이 적용된다.
먼저, R은 현재 함수의 안에서 찾아보고,
다음으로 함수가 정의된 곳을 찾아보고(없으면 한 레벨 위씩 올라가서 global env까지),
마지막으로 다른 로드된 패키지들에서 찾아본다.
다음의 코드는 어떤 결과물이 나올지를 예상해보자.
x <- 1
g04 <- function() {
y <- 2
i <- function() {
z <- 3
c(x, y, z)
}
i()
}
g04()
같은 규칙이, 다른 함수들로 만들어진 함수들에도 적용된다.
난 이걸 찍어낸 함수manufactured function라고 부른다.
이건 10장의 주제다.
6.4.2 Function versus variables
R에서는, 함수도 일반적인 오브젝트이다.
이 말인즉슨, 위에서 설명했던 scoping rule이 함수에도 똑같이 적용된다는 말이다.
g07 <- function(x) x + 1
g08 <- function() {
g07 <- function(x) x + 100
g07(10)
}
g08()
## [1] 110
하지만, 만약에 함수와, 함수가 아닌 것이, 똑같은 이름을 갖는다면,(물론 둘은 서로 다른 env에 있어야겠지만)
이 규칙을 적용하는 것이 조금은 더 복잡해진다.
However, when a function and a non-function share the same name (they must, of course, reside in different environments),
applying these rules gets a little more complicated.
함수 호출에서 이름을 사용할 때, R은 그 값을 찾는데 있어 함수가 아닌 오브젝트들은 애초에 무시한다.
예를 들어 아래의 코드에서, g09는 2개의 다른 값들을 갖는다.
g09 <- function(x) x + 100
g10 <- function() {
g09 <- 10
g09(g09)
}
g10()
## [1] 110
그러니깐 g09()를 찾는데 있어 함수가 아니면 애초에 고려를 하지도 않아서 함수 안의 10의 값을 갖는 g09를 제끼고,
함수 밖의 g09()라는 함수를 잘 찾는 것.
물론 분명히 말하건대, 다른 것들에 대해 같은 이름을 사용하는 것은 헷갈리고, 피하는 것이 가장 좋다!
6.4.3 A fresh start
함수 호출invocation을 여러 번 하는데 있어, 값들values에는 무슨 일이 일어날까?
What happens to values between invocations of a function?
아래의 예를 보자. 아래의 함수를 처음으로 실행하면 무슨 값을 얻을까? 두 번째로 실행할 때는?
(exists()를 본 적이 없다면, 그 이름으로 된 변수가 존재한다면 TRUE를 return하고 아니면 FALSE를 return)
g11 <- function() {
if (!exists("a")) {
a <- 1
} else {
a <- a + 1
}
a
}
g11()
g11()
g11()이 항상 같은 값을 return한다는 것에 놀랄 수도 있다.
함수가 호출될 때마다, 실행을 호스팅하기 위해 새로운 env가 만들어지기 때문.
This happens because every time a function is called a new environment is created to host its execution.
저번 실행 때 무슨 일이 일어났는지를, 함수가 말해줄 방법은 없다는 것.
각 호출은 완전히 독립적이다. each invocation is completely independent.
이걸 Section 10.2.4에서 다룰 것이다.
call과 invocation?
call도 호출이고 invocation도 호출이라고 번역을 하긴했는데, 분명 차이가 있을거 같아서 찾아봤다.javaScript에서는 구별이 확실히 되는거같은데,
call a function이라고 하면 직접적으로 실행을 하는 것이고,
invoke a function이라고 하면 간접적으로 실행을 하는 것인가보다.
Section 6.2.4 Invoking a function에서,
do.call()처럼 mean()을 호출하는 것도 일종의 간접적인 방법으로 실행하는 거라고 생각해봐도 되겠다.
6.4.4 Dynamic lookup
Lexical scoping은 언제가 아니라, 어디서 값을 찾아볼지를 정하는 것이다.
Lexical scoping determines where, but not when to look for values.
R은 함수가 만들어졌을 때가 아니라, 실행될 때 값을 찾아본다.
R looks for values when the function is run, not when the function is created.
실행될 때, 그리고 어디서.
이 2개를 종합해보면, 함수의 output은 함수 env 외부 오브젝트들에 따라 달라질 수 있다는 것.
Together, these two properties tell us that the output of a function can differ depending on the objects outside the function's environment.
g12 <- function() x + 1
x <- 15
g12()
## [1] 16
x <- 20
g12()
## [1] 21
이러한 행동은 꽤 짜증날 수 있다.
코드에 스펠링 실수를 했다면, 함수를 생성할 때 아무런 에러 메세지를 얻지 못한다.
그리고 실수를 하지 않았어도, global env에 정의된 변수들에 따라, 함수를 실행할 때 아무런 에러 메세지를 얻지 못할수도 있다.
이러한 문제를 감지하기 위해, codetools::findGlobals()를 사용하자.
이 함수는 함수 내의 모든 외부 종속성들dependencies(unbound symbol)을 나열한다.
This function lists all the external dependencies (unbound symbols) within a function:
unbound symbols?
그러니깐 name에는 value가 associate되어있는게 일반적인데, value가 없는 name, 예를 들어+를 unbound symbol이라고 하는듯
codetools::findGlobals(g12)
## [1] "+" "x"
이 문제를 해결하기 위해서, 함수의 env를 emptyenv()로 manual하게 바꿀 수 있다.
아무것도 없는 env임.
environment(g12) <- emptyenv()
g12()
## Error in x + 1: 함수 "+"를 찾을 수 없습니다
문제와 해결법을 보고나면, 왜 이런 원치않아보이는 행동이 존재하는지를 알게 된다.
R은 하나부터 끝까지, 뭘 찾든간에, lexical scoping에 의존하고 있다.
mean()과 같이 명백해보이는 것들에서부터 시작해서, 좀 덜 명백해보이는 +나 { 같은 것들까지.
이것은 R의 scoping rule에 좀 아름다운 단순함을 부여한다.
6.4.5 Exercises
6.5 Lazy evaluation
R에서, 함수 인자들function arguments은 lazily evaluated된다.
접근되었을 때만 evaluate된다는 것.
예를 들어, 이 코드는 에러가 나오지 않는다. 왜냐하면 x는 전혀 사용되지 않았기 때문.
h01 <- function(x) {
10
}
h01(stop("This is an error!"))
## [1] 10
그러니깐, 원래 stop() 함수는 에러를 내는 함수임.
그래서 h01(stop("This is an error!")) 하면 에러가 나와야 할 것 같지만,
h01()이라는 함수는 x를 받는데 body에는 x가 없으니 evaluate할 필요가 없어서,
에러가 안 나온다. 이런 얘기.
이건,
함수 인자들에, 필요할 때만 evaluate되는, 잠재적으로 값비싼 계산을 포함시키는 것과 같은 일을 할 수 있기 때문에,
중요한 기능feature이다.
6.5.1 Promises
lazy evaluation은, promise라고 부르는 데이터 구조data structure로 작동power된다.
promise는, 덜 흔하게는 thunk라고 부른다.
이건 R을 흥미로운 프로그래밍 언어로 만드는 기능 중 하나다.
(Section 20.3에서 promises에 대해 다시 다룰 것이다.)
promise는 3개의 요소components들을 가지고 있다.
① expression, x + y와 같은, delayed computation을 발생시킨다.
② environment는 expression이 evaluate되는 장소다. 즉, environment는 함수가 호출되는 곳이다.
그래서 다음의 함수는 101이 아닌, 11을 return한다.
y <- 10
h02 <- function(x) {
y <- 100
x + 1
}
h02(y)
## [1] 11
그리고, 함수 호출 안에서 할당assignment을 하면, 변수는 함수 안이 아닌, 밖에서 bound된다.
h02(y <- 1000)는 무슨 값이 나올까? 변수가 함수 안이 아닌 밖에서 bound된다고 했으니,
y <- 1000
h02 <- function(x) {
y <- 100
x + 1
}
h02(y)
와 같은 것이다.
즉, h02(y <- 1000)은 1001이 나온다.
h02(y <- 1000)
## [1] 1001
y
## [1] 1000
③ value는 promise가 처음으로 접근되었을 때 계산되고 캐시cache되는 것.
expression이 특정한 env에서 evaluate되었을 때,
value는, promise가 처음 access되었을 때 계산되고 캐시cache된다.
A value, which is computed and cached the first time a promise is accessed when
the expression is evaluated in the specified environment.
이래서 promise는 최대 한 번 evaluate되고, 다음의 예에서 "Calculating..."은 한 번만 보게 된다.
double <- function(x) {
message("Calculating...")
x * 2
}
h03 <- function(x) {
c(x, x)
}
h03(double(20))
## Calculating...
## [1] 40 40
R 코드로는 promises를 조작manipulate할 수 없다.
promises는 마치 퀀텀 상태quantum state와 비슷하다.
R 코드로 이걸 검사inspect해보려고 하면, 즉시 evaluation이 실행되어서, promise가 사라지게 될 것이다.
나중에 Section 20.3에서 quosure에 대해 배울 것이다.
얘는 promise를 R 오브젝트로 바꿔서, expression과 environment를 쉽게 검사해볼 수 있다.
6.5.2 Default arguments
lazy evaluation 덕분에, 디폴트 값들이 다른 인자들arguments로 정의될 수 있다.
심지어는, 나중에 함수 안에서 정의될 변수들variables로도 디폴트 값을 정의할 수 있다.
다음의 예를 보면 이해된다.
h04 <- function(x = 1, y = x * 2, z = a + b) {
a <- 10
b <- 100
c(x, y, z)
}
h04()
## [1] 1 2 110
여기서 보면, y는 x라는 다른 인자로 정의되었고, z는 함수 안에서 정의될 변수들 a, b로 정의되었다.
많은 base R 함수들이 이러한 테크닉을 사용하지만, 나는 이걸 추천하지 않는다.
이러면 코드가 더 이해하기 힘들기 때문.
무엇이 return될지 예상하기 위해,
정확히 어떤 순서로 디폴트 인자들arguments이 evaluate되는지를 알아야한다.
그런데,
디폴트 인자들arguments이 evaluate되는 env와, 사용자가 공급한 인자들이 evaluate되는 env가 살짝 다르다.
The evaluation env is slightly different for default and user supplied arguments.
디폴트 인자들은 함수 안에서 evaluate된다.
그래서 보기엔 똑같아 보이는 호출들도 다른 값들을 return할 수 있다.
다음의 극단적인 예를 보자.
h05 <- function(x = ls()) {
a <- 1
x
}
h05()
## [1] "a" "x"
이렇게 디폴트 인자들의 경우에는, ls()가 함수 안에서 evaluate된다.
h05(ls())
## [1] "args" "deviation" "double" "f01" "f02"
## [6] "funs" "g02" "g03" "g07" "g08"
## [11] "g09" "g10" "g12" "h01" "h02"
## [16] "h03" "h04" "h05" "out" "square"
## [21] "x" "y"
이렇게 사용자 공급 인자들의 경우에는, ls()가 global env에서 evaluate된다.
6.5.3 Missing arguments
인자들 값이 user에서 오는지 디폴트에서 오는지는, missing()을 이용해서 알 수 있다.
h06 <- function(x = 10) {
list(missing(x), x)
}
str(h06())
## List of 2
## $ : logi TRUE
## $ : num 10
str(h06(10))
## List of 2
## $ : logi FALSE
## $ : num 10
TRUE라면 디폴트, FALSE라면 사용자 공급.
하지만, missing()은 덜 사용하는 것이 제일 좋다. missing() is best used sparingly, however.
sample() 함수를 예로 들어보자.
몇 개의 인자들arguments이 요구되는가?
args(sample)
## function (x, size, replace = FALSE, prob = NULL)
## NULL
x와 size는 꼭 필요한 것처럼 보인다.
하지만 만약 size를 주지 않으면, sample()은 디폴트를 제공하기 위해 missing()을 이용한다.
(sample을 콘솔 창에 그냥 입력해보면, missing(size)가 등장하는 것을 볼 수 있음.)
이 함수를 내가 다시 써본다면, size가 꼭 필요한 것은 아니지만 값을 넣을 수는 있다고, explicit하게 NULL을 써 줄 것이다.
sample <- function(x, size = NULL, replace = FALSE, prob = NULL) {
if (is.null(size)) {
size <- length(x)
}
x[sample.int(length(x), size, replace = replace, prob = prob)]
}
만약 여기서 %||%라는 삽입 연산자infix operator를 사용해서, 위에 새롭게 쓴 sample()을 더 간단하게 만들 수 있다.
(삽입 연산자라는건 기호의 왼쪽 오른쪽에 뭐가 있다는 거임. 그러니깐 3 + 4처럼. +도 infix operator임. Section 6.8에서 배우게 됨.)
이 기호는, 간단하게 말해, NULL이라면 오른쪽을 사용하고, NULL이 아니라면 왼쪽을 사용한다는 뜻이다.
`%||%` <- function(lhs, rhs) {
if (!is.null(lhs)) {
lhs
} else {
rhs
}
}
sample <- function(x, size = NULL, replace = replace, prob = NULL) {
size <- size %||% length(x)
x[sample.int(length(x), size, replace = replace, prob = prob)]
}
lazy evaluation 덕분에, 불필요한 계산에 대해 걱정할 필요가 없다.
%||%은 size가 NULL이 아닐때만 evaluate될 것이다.
6.5.4 Exercises
6.6 ... (dot-dot-dot)
함수들은 특별한 인자argument인 ...(dot-dot-dot이라고 읽음)을 가질 수 있다.
이것과 함께라면, 함수는 몇 개든 추가적인 인자들arguments을 가질 수 있다.
다른 프로그래밍 언어들에서는, 이러한 타입의 인자를 종종 varargs(variable arguments의 줄임말)라고 부른다.
그리고 이 인자를 사용하는 함수를 variadic이라고 부른다.
다른 함수에게 추가적인 인자들을 전달하는데 ...을 사용할 수도 있다.
i01 <- function(y, z) {
list(y = y, z = z)
}
i02 <- function(x, ...) {
i01(...)
}
str(i02(x = 1, y = 2, z = 3))
## List of 2
## $ y: num 2
## $ z: num 3
..N으로 시작하는, 특별한 형식form을 사용하면, ...에서 해당하는 elements를, 포지션position으로 refer해줌.
i03 <- function(...) {
list(first = ..1, third = ..3)
}
str(i03(1, 2, 3))
## List of 2
## $ first: num 1
## $ third: num 3
i03 <- function(...) {
list(first = ..1, second = ..3)
}
str(i03(1, 2, 3))
## List of 2
## $ first : num 1
## $ second: num 3
이것보다 더 유용한건 list(...)인데, 얘는 arguments를 evaluate하고 list에 저장하는 것.
i04 <- function(...) {
list(...)
}
str(i04(a = 1, b = 2))
## List of 2
## $ a: num 1
## $ b: num 2
rlang::list2()도 확인해봐라. 얘는 쪼개는 것splicing과, 뒤에 쓸데없이 콤마가 붙는 것을 무시하는 것도 지원한다.
예를 들어, list(a = 1, b = 2, ) 이렇게 뒤에 ,가 붙어도 무시하고 해준다는 것.
그리고 rlang::enquos()는 unevaluated 인자들arguments도 캡쳐해준다.
얘는 quasiquotation의 주제다.
음... ...의 2가지 주요한 사용법이 있다.
- 만약에 지금 함수가 다른 함수를 argument로 받는데,
후자의 함수에 추가적인 인자들additional arguments을 전해주고 싶다. 할 때.
아래의 예에서는,lapply()가...를 사용한다.mean()이라는 함수에na.rm을 전달하기 위해서.
x <- list(c(1, 3, NA), c(4, NA, 6))
str(lapply(x, mean, na.rm = TRUE))
## List of 2
## $ : num 2
## $ : num 5
그러니까, lapply()라는 함수가 mean()이라는 함수를 argument로 받는데,
mean()이라는 함수에 na.rm이라는 추가 인자를 전달하기 위해서 ...을 사용한다. 이 뜻.
lapply를 보면 ...이라는 걸 argument로 받고 있는걸 볼 수 있음.
lapply
## function (X, FUN, ...)
## {
## FUN <- match.fun(FUN)
## if (!is.vector(X) || is.object(X))
## X <- as.list(X)
## .Internal(lapply(X, FUN))
## }
## <bytecode: 0x000000001358bf88>
## <environment: namespace:base>
이 테크닉에 대해 Section 9.2.3에서 다시 다룰 것이다.
- 만약 너의 함수가 S3 제네릭generic이라면,
메소드들methods이 임의의 추가 인자들arbitrary extra arguments을 받을 수 있게끔 해주고 싶을 수 있다.
예를 들어서, print()라는 함수를 예로 들어보자.
어떠한 타입의 오브젝트를 print하냐에 따라, 다양한 옵션들이 있기 때문에,
어떤 인자들을 받을건지 미리 다 정해놓을 수는 없다.
그리고 ...가 각각의 메소드들이 그때그때마다 다른 인자들arguments를 받을 수 있게끔 허락해준다.
아래의 예를 보면 그때그때 주는 인자들arguments이 다른 걸 볼 있다.
...이 이걸 가능하게 해주는 것임.
print를 콘솔 창에 쳐보면, 위의 lapply와 마찬가지로 ...가 있는 걸 볼 수 있을 것이다.
print(factor(letters), max.levels = 4)
print(y ~ x, showEnv = TRUE)
이 ...의 사용법에 대해서는 Section 13.4.3에서 다시 다룰 것이다.
...을 사용하는 것에는 2가지 단점이 있다.
-
다른 함수에 인자들arguments을 전달하기 위해 사용할 때에는,
이 인자들이 어디로 가는지 사용자에게 잘 설명해줘야 한다.
그래서lapply()나plot()같은 함수들로 무엇을 할 수 있는지 이해하기가 힘들어진다. -
오타난 인자misspelled argument임에도 에러가 발생하지 않는다. 오타를 알아차리기 힘들게 된다.
sum(1, 2, NA, na_rm = TRUE)
## [1] NA
6.6.1 Exercises
6.7 Exiting a function
대부분의 함수는 두 가지 방법 중 하나로 exit한다.
①성공을 나타내는, 값value을 return하거나, 혹은 ②실패를 나타내는, 에러를 나타낸다.
이 section에서는,
1. 값을 반환하는 것에 대해 다루고(implicit versus explicit, visible versus invisible),
2. 에러에 대해 간략하게 다루어보며,
3. exit handlers를 소개한다. 함수를 exit할 때 코드를 실행하게 해준다.
6.7.1 Implicit versus explicit returns
함수가 값value을 return할 수 있는 2가지 방법이 있다.
- Implicit하게, 즉, 마지막으로 evaluate된 expression이 return되는 값이 되는 것임.
j01 <- function(x) {
if (x < 10) {
0
} else {
10
}
}
j01(5)
## [1] 0
j01(15)
## [1] 10
- Explicit하게, 즉,
return()을 호출해서 쓰는 것임.
j02 <- function(x) {
if (x < 10) {
return(0)
} else {
return(10)
}
}
j02(5)
## [1] 0
j02(15)
## [1] 10
6.7.2 Invisible values
대부분의 함수들은 눈에 보이게 return한다.
그냥 interactive context에다가 함수를 호출하면, 결과물을 출력한다.
(콘솔에다가 함수를 호출하면 결과물이 나온단 소리임)
j03 <- function() 1
j03()
## [1] 1
그러나, 마지막 값last value에다가 invisible()을 씌워서, 자동적으로 프린트되는 것을 막을 수 있다.
j04 <- function() invisible(1)
j04()
이 값이 진짜로 존재한다는 걸 증명하려면, explicit하게 print하던가, 괄호로 감싸주면 된다.
print(j04())
## [1] 1
(j04())
## [1] 1
혹은, withVisible()을 사용해, value랑 보이는지 안보이는지 visibility flag도 return하게끔 할 수 있다.
str(withVisible(j04()))
## List of 2
## $ value : num 1
## $ visible: logi FALSE
invisible하게 return하는 가장 흔한 함수는, <-다.
a <- 2
(a <- 2)
## [1] 2
이게 체인 할당chain assignments이 가능한 이유다.
a <- b <- c <- d <- 2
일반적으로, side effect 때문에 호출되는 모든 함수들은, invisible value를 return해야 한다.
그런 함수들의 예를 들자면 <-, print(), plot() 같은 것들,
그리고 return하는 invisible value는 보통 첫 번째 인자의 값.
6.7.3 Errors
함수가 할당된 작업assigned task을 완수할 수 없다면, stop()과 함께 에러가 나온다.
stop()은 즉시 함수의 실행을 종료한다.
j05 <- function() {
stop("I'm an error")
return(10)
}
j05()
## Error in j05(): I'm an error
에러는 뭔가가 잘못되었다는 걸 알려주며, 유저가 문제를 해결하게끔 강제한다.
C, Go, Rust 같은 몇몇 언어들은 문제들을 알려주는 특별한 return 값들이 있다.
그러나 R에서는 항상 에러가 나와야 한다.
8장에서 에러들과 이것들을 어떻게 다루어야 하는지 배울 것이다.
6.7.4 Exit handlers
가끔 함수는 global state에 임시적인 변화들changes을 필요로 할 수 있다.
하지만 이러한 변화들changes을 나중에 치우는게clean-up 힘들 수 있다.(만약 에러가 생긴다면? 어떻게 복구할건지?)
어떻게 함수가 exit되던간에,
이러한 변화들이 취소undone되고 global state가 복구되었다는걸 보장하기 위해서는,
exit handler를 셋업하기 위해 on.exit()을 사용하자.
다음의 간단한 예는, 함수가 정상적으로 exit되든 에러로 exit되든,
exit handler가 실행된다는 것을 보여준다.
j06 <- function(x) {
cat("Hello\n")
on.exit(cat("Goodbye!\n"), add = TRUE)
if(x) {
return(10)
} else {
stop("Error")
}
}
j06(TRUE)
## Hello
## Goodbye!
## [1] 10
j06(FALSE)
## Hello
## Error in j06(FALSE): Error
## Goodbye!
on.exit()을 사용할 때는 add = TRUE로 설정해놓자.
만약 그렇지 않으면, 각 on.exit()가 이전의 exit handler를 덮어쓸 것이다.
디폴트가 add = FALSE라서 그럼.
그래서 한 개의 handler만 쓰더라도, add = TRUE로 설정하는 것은 좋은 습관이다.
그래야 나중에 exit handlers를 추가하더라도 문제가 생기지 않을 것이다.
on.exit()는 유용하다.
왜냐하면 다음과 같이, 클린업clean-up을 필요로 하는 코드 바로 다음에, 클린업 코드를 놓으면 되기 때문.
cleanup <- function(dir, code) {
old_dir <- setwd(dir)
on.exit(setwd(old_dir), add = TRUE)
old_opt <- options(stringsAsFactors = FALSE)
on.exit(options(old_opt), add = TRUE)
}
위 코드가 의미하는 것은, 함수 안에서는 새롭게 경로를 설정했다가(old_dir <- setwd(dir)),
on.exit(setwd(old_dir), add = TRUE)로 함수가 끝나고 난 뒤에는 원래의 경로로 복구undone하고(clean-up),
함수 안에서는 데이터 프레임이나 행렬을 읽는 기본 옵션을 바꿨다가(old_opt <- options(stringsAsFactors = FALSE)),
on.exit(options(old_opt), add = TRUE)로 함수가 끝나고 난 뒤에는 원래의 옵션으로 복구undone하는 것(clean-up).
함수 안에서 setwd() 같은 것으로 새롭게 경로를 설정하면, global state에서도 경로가 바뀐다.
직접해서 확인해봐도 됨. ㅇㅇ
lazy evaluation과 함께 써서, 변경된 env에서 코드 블락을 실행시키는, 매우 유용한 패턴을 만들 수 있다.
with_dir <- function(dir, code) {
old <- setwd(dir)
on.exit(setwd(old), add = TRUE)
force(code)
}
getwd()
## [1] "C:/Users/Phil2/Documents/portfolio/docs/Advanced R"
with_dir("~", getwd())
## [1] "C:/Users/Phil2/Documents"
code라고만 써도 evluation이 강제 되기 때문에 force()를 쓰는 것이 꼭 필요하지는 않다.
하지만, force()를 사용하면, 우리가 의도적으로 실행을 강제한다는게 매우 명백해진다.
force()의 다른 사용법들에 대해서는 10장에서 배울 것이다.
withr 패키지는(Hester et al. 2018), 임시적인 state를 셋업해주는 여러가지 다른 함수들을 제공한다.
3.4나 그 이전의 버전 R은, on.exit() expression들은 항상 만들어진 순서대로 실행된다.
j08 <- function() {
on.exit(message("a"), add = TRUE)
on.exit(message("b"), add = TRUE)
}
j08()
## a
## b
위처럼 actions가 특정한 순서대로 일어나야 한다면, 클린업을 하는 것이 까다로워진다.
전형적으로 최근에 추가된 expression이 먼저 실행되기를 원하는 경우엔.
This can make cleanup a little tricky if some actions need to happen in a specific order;
typically you want the most recent added expression to be first.
이걸 3.5 혹은 이후 버전의 R에서는, after = FALSE 옵션을 이용해서 컨트롤할 수 있다.
j09 <- function() {
on.exit(message("a"), add = TRUE, after = FALSE)
on.exit(message("b"), add = TRUE, after = FALSE)
}
j09()
## b
## a
6.7.5 Exercises
6.8 Function forms
R의 계산computations을 이해할 때, 2가지 슬로건을 기억하자.
- 존재하는 모든 것들은 오브젝트다. Everything that exists is an object.
- 일어나는 모든 일들은 함수 호출이다. Everything that happens is a function call.
- John Chambers
R에서 일어나는 모든 일들은 함수 호출의 결과물이지만, 모든 호출들calls이 같은 모습은 아니다.
함수 호출은 4가지 모습으로 나타날 수 있다.
-
prefix: 함수 이름이, 인자들arguments보다 먼저 나옴. 예를 들어
footy(a, b, c)
이게 R의 함수 호출 중 대다수임. -
infix: 함수 이름이 인자들 사이에 나온다. 예를 들어,
x + y.
infix 형식은 많은 수학 연산자들에서 사용되고,%로 시작하고 끝나는 사용자 정의user-defined 함수에서 나온다.
이전에 본%||%같이. -
replacement: 이건 값들values을, 할당assign 받은대로 대체해준다. 예를 들어,
names(df) <- c("a", "b", "c")
사실 prefix 함수들처럼 생기긴했다.
이거 많이 써봤던 것이라서, 쉽게 생각할 수 있는데 조금 다르다. 긴장해야함. -
special:
[[,if,for과 같은 함수들. 일관적인 구조를 갖지는 않지만, R의 문법에서 중요한 역할을 한다.
이렇게 4가지 형식forms이 있긴한데, 사실 하나만 알아도 된다. prefix form.
왜냐하면 모든 호출들을 이걸로 쓸 수 있기 때문.
prefix form으로 다 쓸 수 있는 이 특성을 먼저 보여준 다음, 각 형식들을 하나씩 배울 것이다.
6.8.1 Rewriting to prefix form
R의 흥미로운 특성 중 하나는,
모든 infix, replacement, special form을 prefix form으로 쓸 수 있다는 점이다.
이렇게 하는 것은, 언어의 구조에 대한 이해를 깊게 해주기 때문에 유용하다.
prefix form으로 하다보면, 모든 함수의 '진짜 이름real name'을 알게 되고,
이 함수들을 재미로 혹은 이득을 보기 위해 수정할 수도 있다.
예를 들어서, x + y도 함수 호출function call인데, 여기서 우리가 사용하는 함수가 +이며,
이걸 수정할 수도 있다는걸 알게됨ㅇㅇ
답답하신 분들을 위해
내가 이걸 처음 공부할 땐 참 답답했다. 내가 이해한게 맞는건가싶기도 하고, 빨리 뭔소린지 예를 보고싶기도하고.그러니깐 빨리 몇 가지 예만 후딱 보여주고 넘어가겠다.
먼저,
x + y에서 우리가 사용하는 함수가 +인게 어쩌라고? 그럼, 이 함수에 대한 documentation을 찾고 싶다면?
?+를 쓰면 될까?
> ?+
+
?`+`라고 해야한다.
뭐 대단한거 아닌거 같지만, 밑에서는 더 쓸모있는 것도 나온다. 다음 예는 더 충격적이다.
이 함수를 수정할수도 있다고 했다.
`+` <- function(a, b) a - b
5 + 2
## [1] 3
밑에서 이런 예를 다 설명해준다. 그냥 내가 공부할 때의 답답함이 생각나서 써봤다.
rm("+")
5 + 2
## [1] 7
모든 함수 호출을 다 prefix form으로 쓸 수 있다.
x + y를 `+`(x, y) 이렇게 쓸 수 있고,
names(df) <- c("x", "y", "z")를 `names(df)<-`(df, c('x", "y", "z")) 이렇게 쓸 수 있고,
for(i in 1:10) print(i)를 `for`(i, 1:10, print(i))로 쓸 수 있음.
놀랍게도 R에서는, for을 그냥 일반적인 함수처럼 호출할 수 있다.
이게 R의 모든 조작operation에서 마찬가지다.
이 말인즉슨, prefix function이 아닌 함수의 이름을 알고 있다면, 이걸 바꿀 수 있다는 것.
아래의 예를 보면 뭔 말인지 쉽게 이해가 된다.
`(` <- function(e1) {
if (is.numeric(e1) && runif(1) < 0.1) {
e1 + 1
} else {
e1
}
}
이건 괄호가 하는 일을 바꾼 것이다.
이러면 10%의 확률로, 괄호 안의 숫자 계산에다가 1을 더해버림.
replicate(50, (1 + 2))
## [1] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 4 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 4 3 3 3 3
## [36] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
rm("(")
물론, 이렇게 이미 만들어져 있는built-in 함수들을 override하는 것은 나쁜 아이디어다.
하지만, Section 21.2.5에서 배우게 될건데, 정해진 코드 블락에서만 적용하도록 할 수도 있다.
이러면 도메인 특화 언어domain specific languages을 작성하고,
다른 언어로 번역translate하는 것에 대한 깔끔하고 우아한 접근을 할 수 있게 해준다.
더 유용한 응용은, 함수형 프로그래밍 툴들functional programming tools을 쓸 때이다.
예를 들어, add()라는 함수를 먼저 정의해서, 리스트의 모든 elements에 3을 더하는 작업을 하는데 있어,
lapply()를 쓸 수도 있다.
add <- function(x, y) x + y
lapply(list(1:3, 4:5), add, 3)
## [[1]]
## [1] 4 5 6
##
## [[2]]
## [1] 7 8
하지만 그냥 이미 존재하는 +라는 함수를 이용해서도 같은 결과를 얻을 수 있다.
lapply(list(1:3, 4:5), `+`, 3)
## [[1]]
## [1] 4 5 6
##
## [[2]]
## [1] 7 8
이 아이디어를 Section 9에서 다룰 것이다.
6.8.2 Prefix form
접두 형식prefix form은 R 코드에서 가장 흔한 형식이다.
그리고 대부분의 프로그래밍 언어에서 마찬가지임.
R에서 접두 호출prefix calls는, 인자들arguments을 3가지 방식으로 정할 수 있다는 점에서 조금 특별하다.
- position으로. 예를 들어,
help(mean) - 부분 매칭partial matching으로. 예를 들어,
help(top = mean) - 이름name으로. 예를 들어,
help(topic = mean)
topic이라는 이름 대신 그 부분인 top으로도 매칭이 argument specify가 가능하다는 것.
아래의 예에서 3가지를 다 써보았다.
k01 <- function(abcdef, bcde1, bcde2) {
list(a = abcdef, b1 = bcde1, b2 = bcde2)
}
str(k01(1, 2, 3))
## List of 3
## $ a : num 1
## $ b1: num 2
## $ b2: num 3
이러면 position으로 매칭을 한 것이고,
str(k01(2, 3, abcdef = 1))
## List of 3
## $ a : num 1
## $ b1: num 2
## $ b2: num 3
이러면 이름name으로 매칭을 한 것이고,
str(k01(2, 3, a = 1))
## List of 3
## $ a : num 1
## $ b1: num 2
## $ b2: num 3
이러면 unique한 앞글자로 매칭을 한 것.
str(k01(1, 3, b = 2))
## Error in k01(1, 3, b = 2): argument 3 matches multiple formal arguments
이러면 unique한 앞글자가 아니었기 때문에, 애매함ambiguity으로 인한 에러가 발생한다.
일반적으로, 인자 한 두개만 받는 것에 대해서는, positional 매칭을 사용하자.
가장 흔하게 사용되는 것임. 그리고 대부분의 독자들이 그게 무엇인지를 안다.
예를 들어, sample(1:10, 3) 같은 것.
하지만 흔하지 않게 이용되는 인자들arguments에 대해서는, 이러한 positional 매칭을 쓰지말자.
그리고 부분partial 매칭은 절대 쓰지말자.
불행히도 이러한 부분 매칭을 하는 것을 금지시킬 방법은 없는데,
warnPartialMatchArgs 옵션을 사용해서 warning이 뜨게끔 할 수는 있다.
options(warnPartialMatchArgs = TRUE)
x <- k01(a = 1, 2, 3)
## Warning in k01(a = 1, 2, 3): partial argument match of 'a' to 'abcdef'
6.8.3 Infix functions
삽입 함수infix functions는, 함수가 인자들arguments 사이에 위치하기 때문에 이러한 이름이 붙었다.
R에는 이미 만들어져 있는 삽입 함수들이 있다.
:, ::, :::, $, @, ^, *, /, +, -, >, >=, <, <=, ==, !=, !, &, &&, |, ||, ~, <-, <<-
그리고 %로 시작하고 끝나는, 너만의 infix 함수들을 만들수도 있다.
(이전에 %||% 처럼)
그리고 base R은, 이러한 패턴을 %%. %*%, %/%, %in%, %o%, %x%을 정의하는데 사용하고 있다.
자신만의 infix 함수를 정의하는 것은 단순하다.
그냥 2개의 arguments를 갖게 하는 함수를 만들면 된다.
`%+%` <- function(a, b) paste0(a, b)
"new" %+% "string"
## [1] "newstring"
infix 함수의 이름은 보통 R 함수이름보다 좀 더 자유롭게 지을 수 있다.
%을 제외한 어떠한 character의 sequence도 가능하다.
물론, 가끔 특별한 캐릭터들은 escape해주긴 해야한다.
`% %` <- function(a, b) paste(a, b)
`%/\\%` <- function(a, b) paste(a, b)
"new" % % "string"
## [1] "new string"
"new" %/\% "string"
## [1] "new string"
R의 디폴트 우선순위 규칙precedence rule은,
infix 연산자는 왼쪽에서 오른쪽으로 구성되어야 한다는 것이다.
R’s default precedence rules mean that infix operators are composed left to right:
`%-%` <- function(a, b) paste0("(", a, " %-% ", b, ")")
"a" %-% "b" %-% "c"
## [1] "((a %-% b) %-% c)"
그런데, 하나의 인자single argument만 가지고 호출할 수 있는, 2개의 특별한 infix 함수들이 있다.
+와 -.
-1
## [1] -1
+10
## [1] 10
6.8.4 Replacement functions
대체 함수replacement functions는 인자를 수정하는 것처럼 행동한다.
그리고 xxx <-라는 특별한 이름을 가지고 있다.
항상 x와 value라는 인자들arguments을 가져야 하며, 꼭 수정된 오브젝트를 return해야한다.
예를 들어, 다음의 함수는 어떤 벡터의 두 번째 element를 수정한다.
`second<-` <- function(x, value) {
x[2] <- value
x
}
대체 함수는, <-의 왼쪽 편에 함수 호출을 둠으로써 사용된다.
x <- 1:10
second(x) <- 5L
x
## [1] 1 5 3 4 5 6 7 8 9 10
왜 대체 함수가 인자를 수정하는 것처럼 행동한다고 했냐면,
Section 2.5에서 다뤘듯, 사실은 수정된 카피modified copy를 만드는 것이기 때문.
이걸 tracemem()을 통해 볼 수 있다.
x <- 1:10
tracemem(x)
## [1] "<0000000015F48B00>"
second(x) <- 6L
## tracemem[0x0000000015f48b00 -> 0x0000000016ad6c00]: eval eval withVisible withCallingHandlers handle timing_fn evaluate_call <Anonymous> evaluate in_dir block_exec call_block process_group.block process_group withCallingHandlers process_file <Anonymous> <Anonymous>
## tracemem[0x0000000016ad6c00 -> 0x0000000016ad8170]: second<- eval eval withVisible withCallingHandlers handle timing_fn evaluate_call <Anonymous> evaluate in_dir block_exec call_block process_group.block process_group withCallingHandlers process_file <Anonymous> <Anonymous>
만약 대체 함수가 추가적인 인자들additional arguments을 필요로 한다면,
x와 value 사이에 놓고, 대체 함수의 왼쪽에 이것들을 둔채로 호출해라.
말로 설명하려면 더 힘들다. 그냥 밑의 예를 보자.
`modify<-` <- function(x, position, value) {
x[position] <- value
x
}
modify(x, 1) <- 10
## tracemem[0x0000000016ad8170 -> 0x0000000016abeea0]: eval eval withVisible withCallingHandlers handle timing_fn evaluate_call <Anonymous> evaluate in_dir block_exec call_block process_group.block process_group withCallingHandlers process_file <Anonymous> <Anonymous>
## tracemem[0x0000000016abeea0 -> 0x0000000016abef10]: modify<- eval eval withVisible withCallingHandlers handle timing_fn evaluate_call <Anonymous> evaluate in_dir block_exec call_block process_group.block process_group withCallingHandlers process_file <Anonymous> <Anonymous>
## tracemem[0x0000000016abef10 -> 0x0000000016adaa08]: modify<- eval eval withVisible withCallingHandlers handle timing_fn evaluate_call <Anonymous> evaluate in_dir block_exec call_block process_group.block process_group withCallingHandlers process_file <Anonymous> <Anonymous>
사실 modify(x, 1) <- 10이라고 칠 때, R은 뒤에서 이걸 이렇게 바꾸고 있다.
x <- `modify<-`(x, 1, 10)
다른 함수들과 replacement를 결합하는 것은, 조금 더 복잡한 translation을 필요로 한다.
Combining replacement with other functions requires more complex translation.
예를 들어,
x <- c(a = 1, b = 2, c = 3)
names(x)
## [1] "a" "b" "c"
names(x)[2] <- "two"
names(x)
## [1] "a" "two" "c"
이러면 사실 어떤 작업이 일어나고 있는거냐면,
어떻게 translate될 수 있냐면,
`*tmp*` <- x
x <- `names<-`(`*tmp*`, `[<-`(names(`*tmp*`), 2, "two"))
rm(`*tmp*`)
임시 변수 *tmp*를 진짜로 만들어서 쓴 다음, 제거하는 것이다.
6.8.5 Special forms
마지막으로, 특별한 형식으로 작성된 언어 특성들이 있는데, 물론 이것들도 prefix form으로 쓸 수 있다.
괄호들(소괄호, 중괄호)도 여기에 포함된다.
(x)를 `(`)(x) 이렇게 쓸 수 있고,
{x}를 `{`(x) 이렇게 쓸 수 있다.
대괄호는? 얘는 subsetting으로 이용한다는 걸 잊지말자...
subsetting 연산자operator들도,
x[i]를 `[`(x, i) 이렇게 쓸 수 있고,
x[[i]]를 `[[`(x, i) 이렇게 쓸 수 있다.
그리고 컨트롤 플로우control flow의 도구들tools도.
if (cond) true 를 if`(cond, true)`` <br /> `if (cond) true else false` 를if(cond, true, false)`` <br />for(var in seq) action를 ```for(var, seq, action)<br /> `while(cond) action` 을 ```while`(cond, action)
repeat expr 을 repeat`(expr)`` <br /> `next` 를next()`` <br />break` 를 break
마지막으로, 가장 복잡한 건 function이라는 함수다.
function(arg1, arg2) {body} 를 `function`(alist(arg1, arg2), body, env)로 쓸 수 있음.
특별한 형식special form 밑의 함수의 이름을 정확히 알면, documentation을 얻는데 도움이 된다.
?(라고 하면 syntax error가 발생한다.
`?(```라고 해야 괄호에 대한 documentation을 볼 수 있다.
모든 특별한 형식들은 원시 함수로 고안implement되어 있다(C언어 같은).
그래서 이 함수들은 print해봐야 별 도움이 안 된다.
`for`
## .Primitive("for")
6.8.6 Exercises
6.9 Quiz answers
-
formal, body, environment
-
11이 return됨. 20이 아니고.
-
(2 * 3) + 1 -
mean(x = c(1:10, NA), na.rm = TRUE) -
에러 안 나옴. 왜냐하면 뒤의
stop("This is an error!")는 evaluate되지도 않아서.
두 번째 인자argument는 사용되지 않아서, evaluate되지도 않음. lazy evaluation. -
infix 함수들은 무엇이고 어떻게 만드는지? Section 6.8.3, Section 6.8.4
-
on.exit()을 사용. Section 6.7.4